Hyperparameter Optimization: Distributed Hardware-Aware and Homotopy-Based Strategies
Spring 2017 - Present
Description
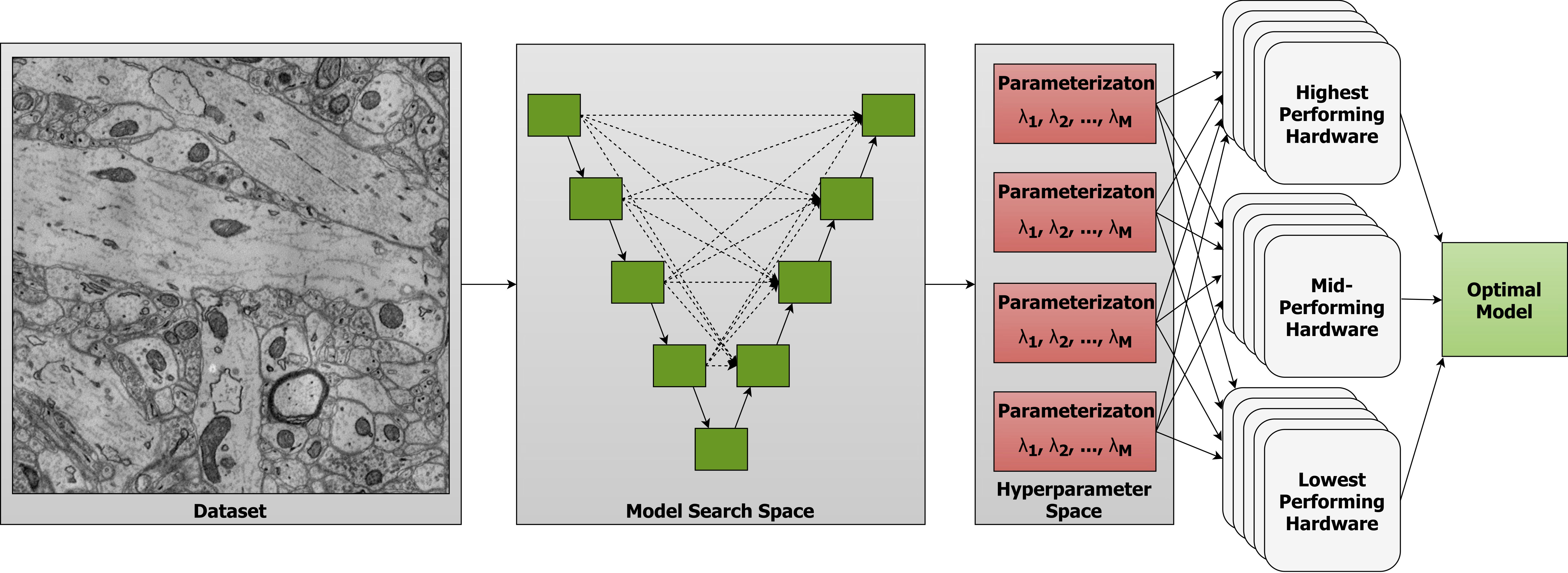
Computer vision is experiencing an AI renaissance, in which machine learning models are expediting important breakthroughs in academic research and commercial applications. Effectively training these models, however, is not trivial due in part to hyperparameters: user-configured values that control a model’s ability to learn from data. Existing hyperparameter optimization methods are highly parallel but make no effort to balance the search across heterogeneous hardware or to prioritize searching high-impact spaces.
In this work, we introduce a framework for massively Scalable Hardware-Aware Distributed Hyperparameter Optimization (SHADHO). Our framework calculates the relative complexity of each search space and monitors performance on the learning task over all trials. These metrics are then used as heuristics to assign hyperparameters to distributed workers based on their hardware. We first demonstrate that our framework achieves double the throughput of a standard distributed hyperparameter optimization framework by optimizing SVM for MNIST using 150 distributed workers. We then conduct model search with SHADHO over the course of one week using 74 GPUs across two compute clusters to optimize U-Net for a cell segmentation task, discovering 515 models that achieve a lower validation loss than standard U-Net.
This project also looks at hyperparameter optimization strategies that can enhance existing approaches. Many hyperparameter optimization techniques rely on naive search methods or assume that the loss function is smooth and continuous, which may not always be the case. Traditional methods, like grid search and Bayesian optimization, often struggle to quickly adapt and efficiently search the loss landscape. Grid search is computationally expensive, while Bayesian optimization can be slow to prime. Since the search space for hyperparameter optimization is frequently high-dimensional and non-convex, it is often challenging to efficiently find a global minimum. Moreover, optimal hyperparameters can be sensitive to the specific dataset or task, further complicating the search process. To address these issues, we propose a new hyperparameter optimization method, HomOpt, using a data-driven approach based on a generalized additive model (GAM) surrogate combined with homotopy optimization. This strategy augments established optimization methodologies to boost the performance and effectiveness of any given method with faster convergence to the optimum on continuous, discrete, and categorical domain spaces.
This work was supported by IARPA contract #D16PC00002, the NVIDIA Corporation, DEVCOM Army Research Laboratory under cooperative agreement W911NF-20-2-0218, and the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357
Publications
- "A Flexible Framework for Hyperparameter Optimization Using Homotopy and Surrogate,,,,
Models,"
,,Scientific Reports,Accepted for Publication July 2025.[pdf][bibtex]@article{abraham2025homopt,
title={A Flexible Framework for Hyperparameter Optimization Using
Homotopy and Surrogate Models},
author={Abraham, Sophia J and
Maduranga, Kehelwala DG and
Kinnison, Jeffery and
Carmichael, Zachariah and
Hauenstein, Jonathan D and
Scheirer, Walter J},
journal={Scientific Reports},
year={2025}
}
- "Wavelet-Based Mechanistic Interpretability of Vision Transformers via,,,
Frequency-Aware Ablations,"Proceedings of the 1st Workshop on Mechanistic Interpretability for Vision (MIV 2025),June 2025.[pdf][bibtex]@InProceedings{Abraham_2025_CVPR,
author = {Abraham, Sophia J. and
Hauenstein, Jonathan D. and
Scheirer, Walter J.},
title = {Wavelet-Based Mechanistic Interpretability of Vision Transformers via
Frequency-Aware Ablations},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2025},
pages = {4839-4843}
}
- "Towards Fair and Robust Face Parsing for Generative AI: A Multi-Objective,,,
Approach,"Proceedings of the IEEE Conference on Automatic Face and Gesture Recognition (FG),May 2025.[pdf][bibtex]@inproceedings{abraham2025fairrobustfaceparsing,
title={Towards Fair and Robust Face Parsing for Generative AI:
A Multi-Objective Approach},
author={Sophia J. Abraham and Jonathan D. Hauenstein and Walter J. Scheirer},
booktitle={Proceedings of the IEEE Conference on Automatic Face
and Gesture Recognition (FG)},
year={2025},
}
- "Adaptive Self-supervised Vision Transformers for Multi-sensor Automatic Target,,,,
Recognition,"Proceedings of the SPIE Defense + Commercial Sensing Symposium,April 2025.[pdf][bibtex]@inproceedings{abraham2025multi,
title={Adaptive Self-supervised Vision Transformers for Multi-sensor Automatic Target
Recognition},
author={Abraham, Sophia and
You, Suya and
Hauenstein, Jonathan D and
Scheirer, Walter},
booktitle={Automatic Target Recognition XXXV},
volume={13463},
pages={134630G},
year={2025},
organization={SPIE}
}
- "Multi-Objective Hyperparameter Optimization with Homotopy-Based Strategies for,,,,,
Enhanced Automatic Target Recognition Models,"Proceedings of the SPIE Defense + Commercial Sensing Symposium
(Best Student Paper Award),April 2024.[pdf][bibtex]@inproceedings{abraham2024multi,
title={Multi-objective optimization with homotopy-based strategies for
enhanced multimodal automatic target recognition models},
author={Abraham, Sophia and
Cruz, Steve and
You, Suya and
Hauenstein, Jonathan D and
Scheirer, Walter},
booktitle={Automatic Target Recognition XXXIV},
volume={13039},
pages={1303903},
year={2024},
organization={SPIE}
}
- "NCQS: Nonlinear Convex Quadrature Surrogate Hyperparameter Optimization,",,,,
,Proceedings of the 1st Workshop on Resource Efficient Deep Learning for Computer Vision,October 2023.[pdf][bibtex]@inproceedings{abraham2023ncqs,
title={NCQS: Nonlinear Convex Quadrature Surrogate Hyperparameter Optimization},
author={Abraham, Sophia and
Maduranga, Kehelwala Dewage Gayan and
Kinnison, Jeffery and
Hauenstein, Jonathan and
Scheirer, Walter},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer
Vision},
pages={1195--1203},
year={2023}
}
- "Efficient Hyperparameter Optimization for ATR Using Homotopy Parametrization,",,,,,
,,Proceedings of the SPIE Defense + Commercial Sensing Symposium
(Best Student Paper Award),April 2023.[pdf][bibtex]@inproceedings{abraham2023efficient,
title={Efficient hyperparameter optimization for ATR using homotopy
parametrization},
author={Abraham, Sophia and
Kinnison, Jeffrey and
Miksis, Zachary and
Poster, Domenick and
You, Suya and
Hauenstein, Jonathan
and Scheirer, Walter},
booktitle={Automatic Target Recognition XXXIII},
volume={12521},
pages={15--23},
year={2023},
organization={SPIE}
}
- "Auto-Sizing the Transformer Network: Improving Speed, Efficiency, and Performance, , , , ,
for Low-Resource Machine Translation,"Proceedings of the Workshop on Neural Generation and Translation (WNGT),November 2019.[pdf] [code][bibtex]@InProceedings{MurrayWNGT19,
author = {Kenton Murray and
Jeff Kinnison and
Toan Nguyen and
Walter J. Scheirer and
David Chiang},
title = {Auto-Sizing the Transformer Network: Improving Speed, Efficiency, and Performance
for Low-Resource Machine Translation},
booktitle = {Workshop on Neural Generation and Translation (WNGT)},
year = {2019}
}
- "SHADHO: Massively Scalable Hardware-Aware Distributed Hyperparameter, , , ,
Optimization,"Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV),March 2018.[pdf] [code][bibtex]@InProceedings{KinnisonKTS17,
author = {Jeff Kinnison and
Nathaniel Kremer{-}Herman and
Douglas Thain and
Walter J. Scheirer},
title = {{SHADHO:} Massively Scalable Hardware-Aware Distributed Hyperparameter
Optimization},
booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)},
year = {2018}
}